Archethic's database
Archethic is shipped with a custom database engine built from scratch to support an efficient data storage to support concurrent writes and reads while avoiding much as I/O as possible.
Rationale
Several solutions have been analyzed and uses from benchmarks, to implementation until the need to implement a solution which will fit the needs and requirements. (ie. LevelDB, RocksDB, Cassandra, ScyllaDB, Aerospike, Redis, etc.)
There are multiple database engines which provides different needs, but we wanted to focus on NoSQL and efficient disk amangement and writes.
Our choice ended with log structued family storages (instead of B-tree which are more read efficient, but suffer for random writes)
Log Structured Merge
LSM (Log Structured Merge) comes with the immutable datastructures and append only writes.
Append only writes are really efficient in term of disk I/O as a single seek in the file is needed to be placed at the end of the file, and write the new data.
There are also shipped with inmemory structure which is flush over time while keeping this append-only log on disk for backup and safety measure. So those dumps are immutable and provided the database view at certain time.
But because most of the KeyValue database using LSM, involving updates of keys, they must manage the redundancy of the data and provide cleanup (deleted or updates entries).
To support this clean, they are using compaction which is a merge operation which take only the last data information from multiple immutable dumps.
Log Structured Hash Tables
Log Structured Hash Tables as Bitcask are really interesting as the writing and the reading are efficient because it's using immutable data and key indexing in memory for a predictable and fast reading.
Its main requirement is to hold all the key of the value into the memory otherwise
This approach also invovles a compaction as data blocks are appended with immutability but needs to be merged after some time to avoid filesystem exhaustion.
Our approach
All those database Key-value, Wide column storage, etc.. which are using LSM are considered as global database to support different kind of use cases. However in our case, we have a specific need and requirements: we are only dealing with immutable data at all. The data stored in the transaction will never changed, and the mutation and views are managed from an application perspective but not from the disk itself.
Then we can reduce a lot of effort and I/O which are heavy in term of computations as compaction/merges, dump of memory structures
In additional to it, we can keep some indexing in memory while providing file backup to avoid memory exhaustion and be able to scale more. Evenif we might the indexing on file not efficient, because we are using append only strategy for everything, the indexing is better as the last index bring the last update.
Design
So in order to fullfill all those requirements and optimize performances for our needs, we create a new data layer from scratch. Nevertheless, we took concepts interesting from log structured and wide column storages to support efficient writes/reads with the support of nested column filtering.
Chains storage
The main concept is simple: each chain has its own file.
Each chain is uniquely identified by its genesis address: which is the address of the first's previous public key, aka the 0th address.
![]()
The append-only strategy is straighforward, each time a new transaction in a chain is persisted, the transaction is added at the end of the file of a chain. So in term of disk access and I/O, it requires a simple seek at the end of the file and dumps of the transaction serialized.
This concept led to the streaming capability of the writes to avoid exhaustion of the system (as a backpressure mechanism)
So in order to be able to read specific columns from the transaction, the transaction is serialized in a specific format before to be written to disk. This encoding wraps each key value of the transaction into self-descriptive and schema less write. Each key/value pair is encoded in that way:
| Column name size (1 byte) | Value size (32 byte) | Column name (binary) | Value (binary) |
|---|---|---|---|
| 7 | 33 | Address | 00743B809ADDE7E1E3E9B5AFB704813D06155958FBBB78CD052CC45A1B19F976BE |
However, because we are using a schemaless approach letting the code defining the encoding and decoding, each transaction is prepended by its size length (4 bytes) and its version.
So by this way, we know the boundaries of the transaction within a file and the way to decode it.
Chain indexing
Because each chain has its own file, we need also a mechanism to identify a transaction without a chain, or identify a transaction amongs the chains.
Different kind of indexing are performed some completly both in memory and disks for backup and long term storage.
File indexes
Summary
To provide a way to find a transaction without knowing its genesis address, we implemented a summary index (as there are in other solutions) to help the identify the location of the data. Then, as the BeaconChain used this concept, we also applied the address's subset identification here. So each address contains a subset which is the first byte of the digest (exluding the metadata to identify curve and hash algorithm).
So each subset has its own index, with a list of transaction, genesis addresses, the transaction size and its offset (location in the chain's genesis file)
![]()
Addresses
One principle of the transaction chain is to able to target any address of a chain as recipient. So during the transaction validation, nodes are able to resolve recipient last address and then target the right shard of the chain. They are doing this resolution by asking the recipient shard about the last transaction address.
But in order to make this possible, previous nodes of a given chain need to keep a track of the last transaction of the chain.
Then a specific index file is provided ("Genesis-address"-addresses) for this purpose which contains a given chain (genesis file), a list of timestamps and addresses for this chain.
![]()
The timestamp is useful during replication and validation to be sure to get the last chain address at the time of the validation, so we can reproduce the validation later without problem.
However during the transaction validation we keep the latest one.
Keys
Sometimes we also want to identify the genesis address or first public key of a chain. But we need to track it as well.
For instance, in smart contract code, we want to do some actions depending if a transaction's coming from a specific person, but how to identify it, as its transaction chain evolves and we don't keep a track of all the transactions.
Then being able to identify the first transaction of a chain is important.
So we are adding a new chain index file ("Genesis address"-key) to support this feature.
![]()
Types
We also want to be able to list of the transactions of a given type, this is useful when the starts and fill memory tables but also to list transactions in UI or API for network transactions.
Then a index is given by type for this purpose where the addresses are appended
Memory indexes
Among the files indexes for backup or long term storage, we are proving some in memory indexes (a bit like Log structured Hash tables) to read data with predictable latency. This make reads fast.

Transaction index
This index works a bit like a chache and is identified by a transaction address with the following information:
- genesis address
- offset
- size
So once the a transaction is present in this cache, we can easily read transaction give information about the position of the file, and read it really quickly.
But if the transaction is not present, we can easily use the index summary as fallback, to identify the file and the offset.
Chain stats
This index is built from the genesis chain files and contains information about the number of transactions within and the last offset. So during the write, the transaction index/summary is notified about the last offset of the chain, and help to move forward in the location of new transaction.
Last index
As we mentioned in the last addresses chain index file, we need to quickly know what is the last address of a chain, so here we a cache, we says for a given genesis address what is the latest.
So this table is filled every time a node receives a last address notification.
Type index
Because we have type index file, we can also leverages a memory index to know how many transactions for a given type exists. This is useful for key derivation for network transactions. So we can easily and quickly get the size of a chain.
Chain reader
Wide column storages provides the capability to extract sub columns information to avoid the load of an entire row in the memory to let the application filter the data. The filtering can be done on the disk, while make it efficients.
The behaviour like is a two dimensional key-value pair, where the 1st dimension targets the partition key and the 2nd targets the columns of the row.
So we achieve a similar approach here, by eing the 1st dimension as the chain file and the 2nd as the list of columns names encoded during the transaction write.
- After being able to get the lookup informations from the chain indexes to identify the file and offset in the file of a given transaction, we
seek(put the cursor) at the offset position. - Then we can sequentially read columns and values and pick the ones we want
- When we reached the end of the transaction (thanks to the size information from the indexes) or the enf of file, we convert those values into a transaction where the values retrieved will be filled in to the structure.
Write path
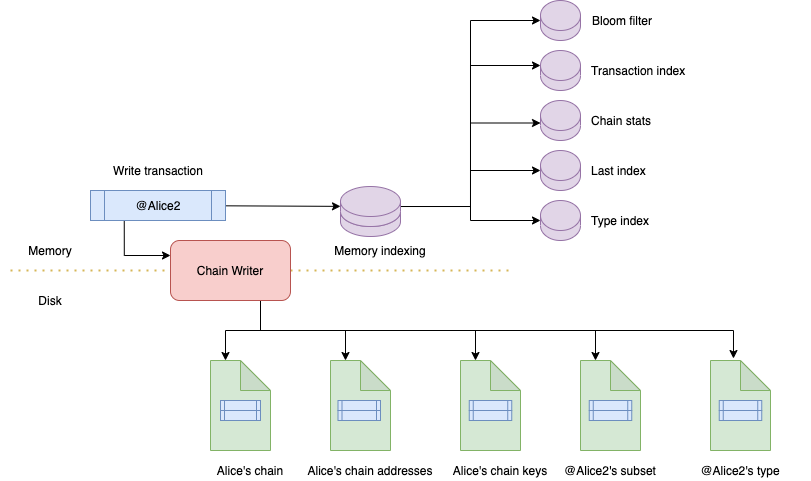
So in order to be written, a transaction follows a write path to make reads efficient.
After a transaction is written to disk in the genesis chain file, several disks and memory writes are performed to help the indexing of this transaction.
Transaction's address is written to:
- the summary index from the subset of the transaction (file)
- the last addresses index of the chain (in memory and file)
- the transaction's type index (in memory)
- the bloom filters (in memory)
- transaction index (in memory)
Its public key is also written to the chain's public key index. (file)
Then transaction's type in memory index number incremented, as well as the chain stats in memory index.
Read path
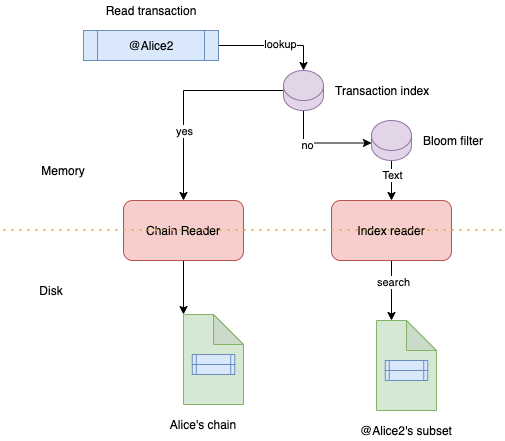
To make read efficients, when a transaction wants to be retrieved, it goes to the read path:
- Check if the transaction index is present, if yes we have information about the file and position
- Otherwise we check the bloom filter, if yes, we read the subset summary to identify the position of the transaction, otherwise you inform the transaction does not exists
- Then a reader is able to perform reads according to the fields requested and the position retrieved.
Additional of-chain storage
For now, we have covered the scope of chain storage and retrieval, however we also need to persist some data which are not really inserted into a chain and are important for well-being of the node execution.
So we have to leverage others kind of storages and indexes as simple key-value in memory loaded from disk.
The scope of those storages are:
- Bootstrapping information (last P2P bootstrapping seeds, storage nonce, last sync date)
- Network statistics (aggregated TPS and nb of transactions)
- P2P view (aggregated node availability from the beacon chain)